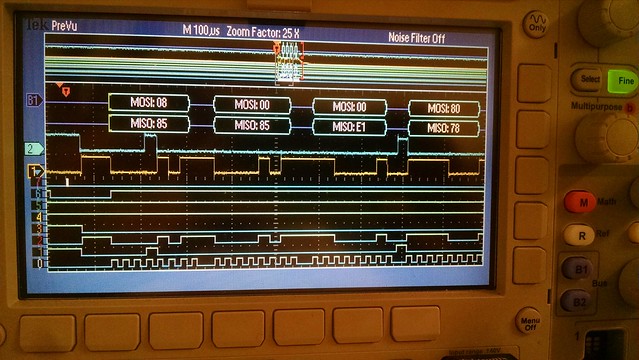
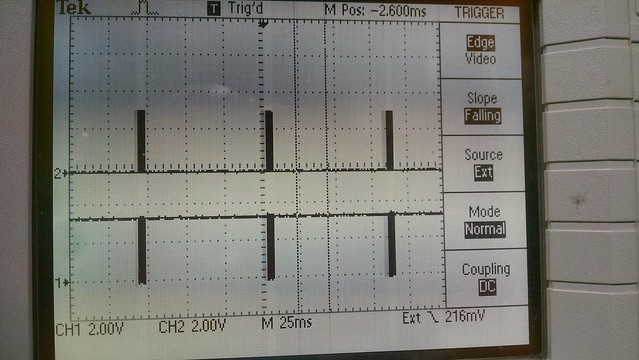
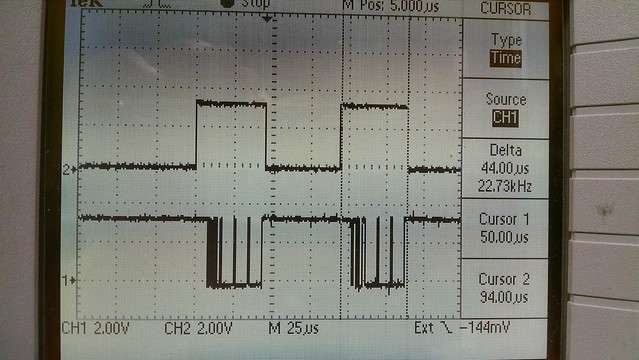
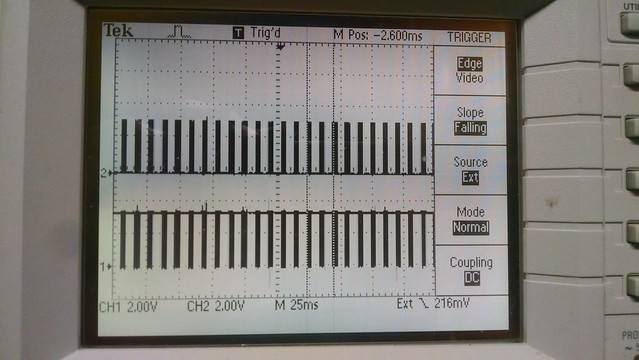
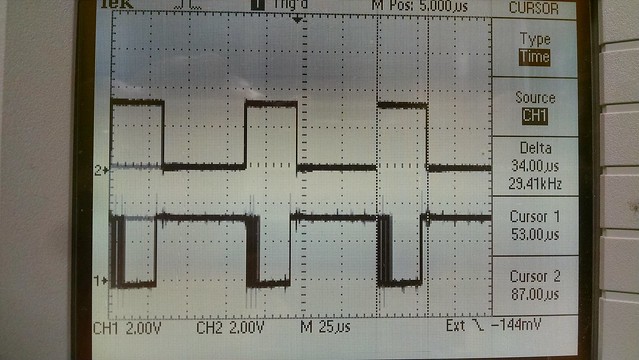
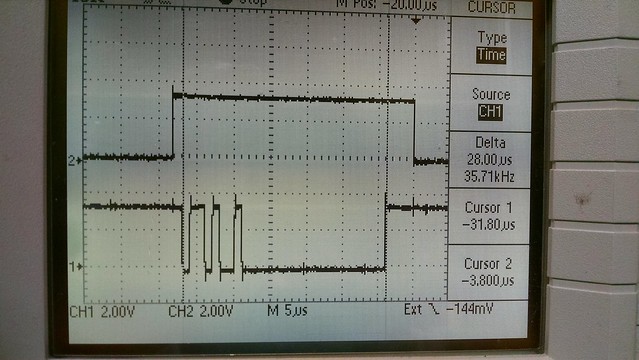
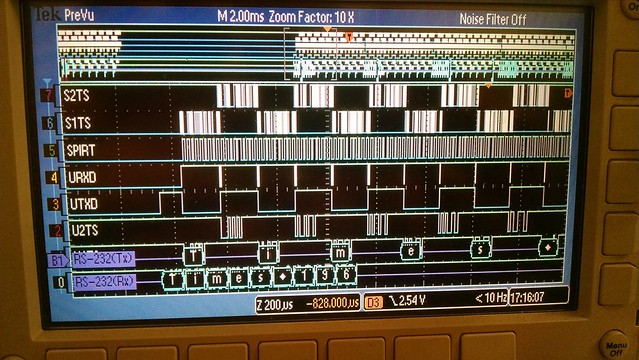
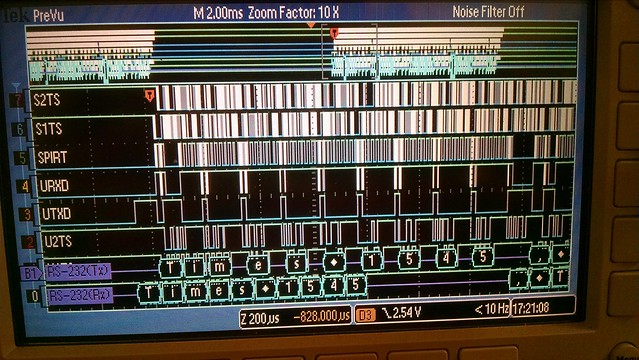
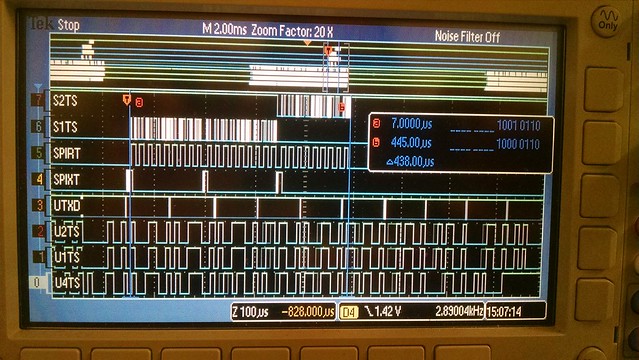
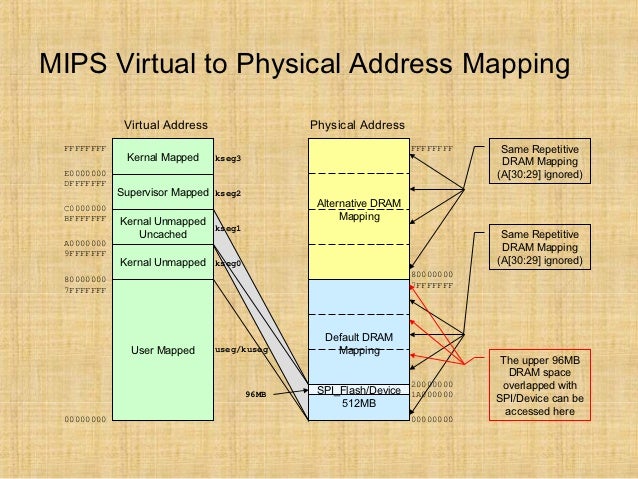
I've just started creating a new (from an existing mips/pic32mz configuration) cpu and board port for this dev board. So far only a few I/O items are working like the debug uart, user leds and rgb led but it boots, runs the 'hello world' and timer serial port examples and the Linux based bare-metal MIPS-MTI compiler/linker creates a mplabx-ipe compatible hex file for flashing.
http://www.microchip.com/Developmen...8Q1&utm_content=DevTools&utm_campaign=Article
Fork for riotos software: http://github.com/nsaspook/RIOT/tree/PIC32MZEF
http://github.com/RIOT-OS/RIOT/wiki/Family:-MIPS
**broken link removed**
working toolchain: http://codescape.mips.com/components/toolchain/2016.05-03/downloads.html
SDK Installers v1.4
Update the Linux shell path (in .bashrc) to include the correct compiler after the tools install.
export PATH=$PATH:/usr/local/go/bin:/opt/imgtec/Toolchains/mips-mti-elf/2016.05-03/bin
http://www.microchip.com/Developmen...8Q1&utm_content=DevTools&utm_campaign=Article
Fork for riotos software: http://github.com/nsaspook/RIOT/tree/PIC32MZEF
http://github.com/RIOT-OS/RIOT/wiki/Family:-MIPS
**broken link removed**
working toolchain: http://codescape.mips.com/components/toolchain/2016.05-03/downloads.html
SDK Installers v1.4
Update the Linux shell path (in .bashrc) to include the correct compiler after the tools install.
export PATH=$PATH:/usr/local/go/bin:/opt/imgtec/Toolchains/mips-mti-elf/2016.05-03/bin
Last edited:


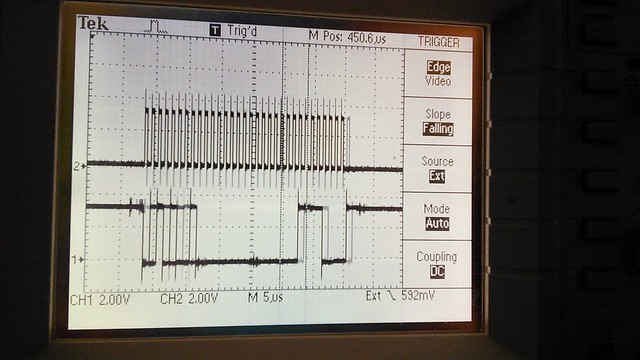
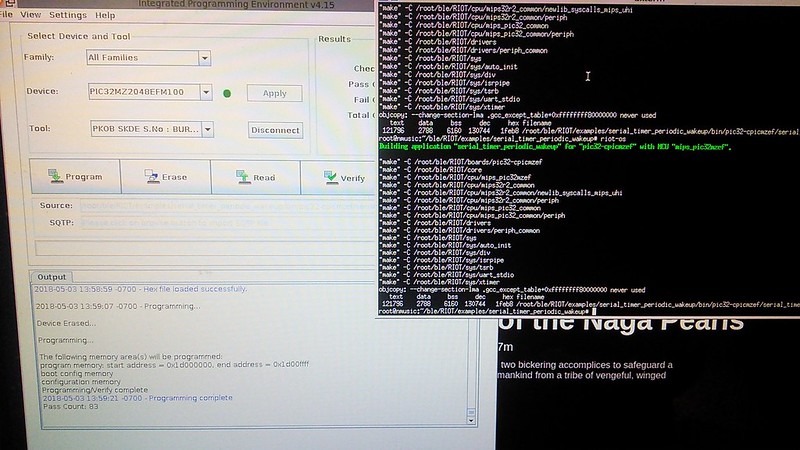
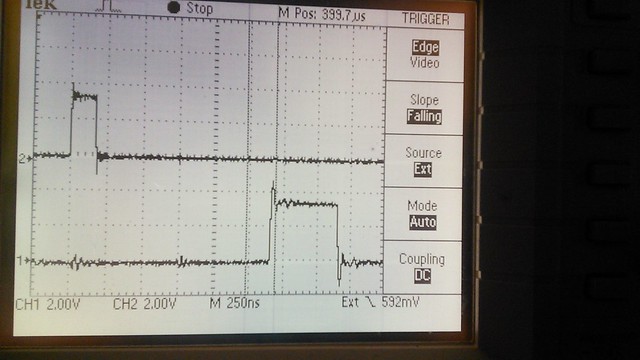



")